

해당 글은 FEConf Korea - 컴포넌트, 다시 생각하기 영상을 보고 정리한 글 입니다.
의존성
케이크를 만드려면밀가루,설탕,계란이 필요하다.케이크는밀가루,설탕,계란에 의존한다. 라는 말과 같은 의미이다.케이크의 의존성:밀가루,설탕,계란
위의 3 문장은 모두 같은 의미이다. 그렇다면 리액트 컴포넌트를 만들려면 어떤 것들이 필요할까?
리액트 컴포넌트는 필요한 것들을 Props나 Hooks, import를 통해 받을 수 있다. 이 요소들은 리액트 컴포넌트가 가진 의존성의 기능적 분류라고 볼 수 있다.
그럼 이러한 요소들은 어떤 특징을 가지고 있을까?
- 스타일 - css, scss 등등
- 컴포넌트에서 쓰이는 특정한 커스텀 로직 - UI를 조작하는 특정한 동작, 리액트 컴포넌트에 의도한 사이드 이펙트를 주거나 할 때 사용, 보통 커스텀 훅의 형태로 작성한다.
- 전역상태 - 유저액션을 통해 초래된 클라이언트의 상태이다. 보통 로그인 정보, URI 표현, 전체메뉴 열고 닫기 등등
- 리모트 데이터 스키마 - API 서버에서 내려주는 데이터.
리팩토링
비슷한 관심사라면 가까운 곳에 두기
- 어떤 부분을 수정할 때 파일들이 서로 멀어지면 집중력이 분산된다.
- 같은 파일 안에 두거나 바로 옆에 두는 것이 좋다.
아래와 같은 구조가 있을 때 어떠한 것을 서로 가까이 둘 수 있을까?
![image]()
- 전역 상태는 여러 컴포넌트가 함께 사용하는 것이기 때문에 함께 두기 힘들 것이다.
스타일 (CSS in js)과 로직은 함께 두는 것을 쉽게 할 수 있을 것이다.
![image]()
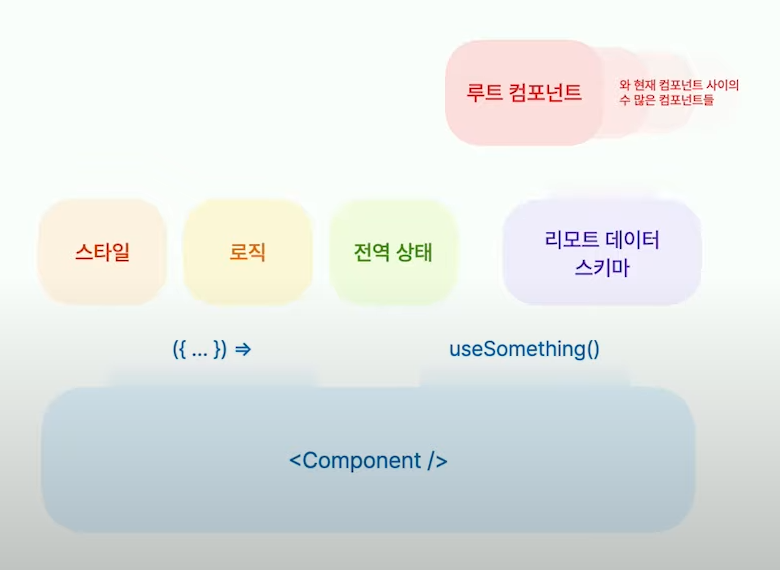

하지만 한 컴포넌트의 크기가 너무 커지게 되는 것을 걱정할 수 있는데 그럴 경우 상위나 하위의 폴더가 아닌 같은 폴더내에 다른 파일로 분리하자
리모트 데이터 스키마와의 의존성

API 서버로부터 리모트 데이터 스키마가 내려오는 모습을 보면, 루트 컴포넌트 -> 다른 컴포넌트 -> 내 컴포넌트의 흐름으로 흐르는 것을 볼 수 있다.
여기서 만약 props를 통해 데이터 스키마를 받게 된다면 아래와 같은 모습일 것이다.
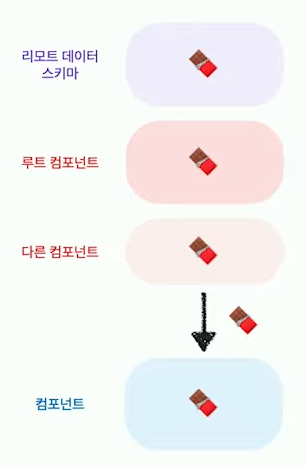
이럴 경우 루트 컴포넌트와 강한 의존성이 생기게 된다.
이것을 개선해 보면 아래와 같이 props를 통해 ID만 받고 데이터 저장소에서 해당ID를 통해 데이터를 받아올 수 있게 해서 의존성을 끊어낼 수 있다.
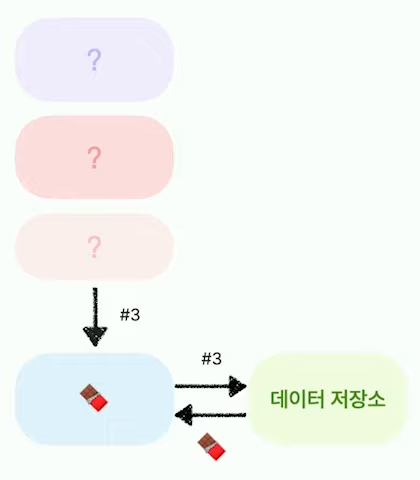
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import { useArticle } from '~/store';
interface Props {
articleId: string;
}
const Something: React.ExoticComponent<Props> = (props) => {
const article = useArticle(props.articleId);
return (
<div>
<h1>{article.title}</h1>
</div>
)
}
데이터를 ID 기반으로 정리하기
만약 API 응답이 다음과 같이 온다고 가정해 보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
id: '123',
author: {
id: '1',
name: 'paul',
},
title: 'My awesome blog post',
comments: [
{
id: '324',
commenter: {
id: '2',
name: 'Nicole',
},
},
],
}
여기서 ID기반으로 특정 객체에 접근한다고 한다면 쉽지 않을 것 같다. 그런데 다음과 같이 API 응답을 정리하면 어떨까?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
result: '123',
entities: {
articles: {
'123': {
id: '123',
author: '1',
title: 'My awesome blog post',
comments: ['324'],
},
},
users: {
'1': { id: '1', name: 'Paul' },
'2': { id: '2', name: 'Nicole' },
},
comments: {
'324': { id: '324', commenter: '2' },
},
},
}
모델명과 ID를 가지고 특정 데이터를 뽑아낼 수 있을 것이다. 이를 데이터 정규화(Normalization)라고 한다. 이런 데이터 정규화를 도와주는 normalizr라는 라이브러리가 있다.
이렇게 리팩토링 함으로써 특정 객체를 데이터 저장소로부터 쉽게 가져올 수 있게 되었지만 여기에는 아직 또다른 숨은 의존성이 생기게 된다.
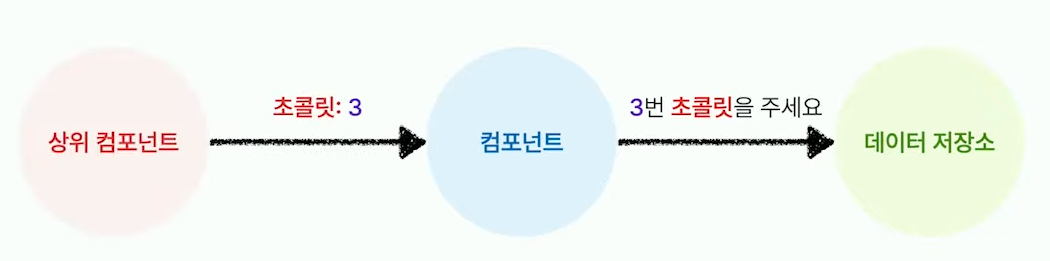
바로 모델을 상위 컴포넌트에서 정확하게 알고있어야 한다는 점이다. 이것을 느슨하게 풀기 위해서 전역 ID (Global ID)를 사용하는 것이다.
전역 ID는 특정 객체를 식별하기 위해 모델명을 따로 넘길 필요 없이 도메인 내에서 유일성을 갖는 ID를 말한다.
보통 모델명과 ID값을 concat 하여 생성하거나 경우에 따라 base64 인코드, 디코드를 할 수도 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Before
// 해당 컴포넌트가 Article이라는 정보가 필요하다는 것 역시 컴포넌트 바깥에서 주입받고 있다.
// import { useArticle } from '~/store';
// After
// 전역 ID를 통해 데이터를 가져오는 훅
import { useNode } from '~/store';
interface Props {
articleId: string;
}
const Something: React.ExoticComponent<Props> = (props) => {
// Before
// const article = useArticle(props.articleId);
// After
// 글로벌 아이디를 활용하여 사용할 데이터의 모델 정보 마저 컴포넌트 내부에 함께 둘 수 있다.
const article = useNode({ on: 'Article' }, props.articleId);
return (
<div>
<h1>{article.title}</h1>
</div>
)
}
Props 이름 짓기
간단한 유저 프로필을 보여주는 컴포넌트가 있다. 이 컴포넌트는 게시물 위에도 붙을 수 있고, 친구 목록등에서 사용될 수 있다.
이 컴포넌트의 리모트 데이터 스키마 의존성은 다음과 같다.
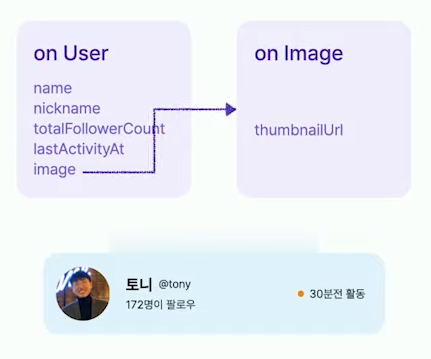
이 컴포넌트는 유저 모델의 네임, 닉네임 등의 필드를 의존하고 있고, 유저 모델에 Image 필드가 가리키는 이미지 모델의 썸네일 url을 의존하고 있는 걸 확인할 수 있다.
그럼 일단 단순하게 props 네이밍을 다음과 같이 해봤다.
1
2
3
4
5
6
7
8
interface Props {
leftImageThumbnailUrl: string;
title: string;
title2: string;
caption: string;
rightDotColor: string;
rightCaption: string;
}
얼핏보면 직관적인것 같지만 사실은 그렇지 않다. 그 이유는 이 컴포넌트에 존재하는 의존성들을 명확하게 나타내 주지 않았기 때문이다.
그래서 여기에 필요한 원칙은 의존한다면 그대로 드러내기이다.
앞에 말했던 의존성을 드러내도록 props 네이밍을 다음과 같이 해보면, 유저와 이미지 모델을 사용하는 것을 그대로 드러냈다.
1
2
3
4
5
6
7
interface Props {
userImageThumbnailUrl: string;
userName: string;
userNickname: string;
userTotalFollowerCount: string;
userLastActivityAt: Date;
}
하지만 아직 여기에도 숨겨진 정보가 있다. 바로 유저와 이미지모델 사이의 관계 정보이다. 이 정보까지 드러내 보면 다음과 같은 모습이 될 것 이다.
1
2
3
4
5
6
7
8
9
10
11
interface Props {
user: {
name: string;
nickname: string;
totalFollowerCount: string;
lastActivityAt: Date;
image: {
thumbnailUrl: string;
}
}
}
훨씬 직관적인 모습이 되었다 👍
그러나😱 한 컴포넌트에서 여러 모델(유저, 이미지)의 정보를 표현하는 것은 어쩌면 관심사의 분리가 제대로 안 되었다는 신호일 수 있다.

따라서 이 컴포넌트를 유저와 이미지로 분리할 수 있다.
하지만 이 부분도 상위 컴포넌트와 의존성(image의 thumbnailUrl)이 생길 것이라고 예상할 수 있다. 그렇기 때문에 아무래도 뭔가 재사용하기 힘들 것 같다.
따라서 앞에서 소개한 전역 ID를 통해 필요한 객체의 래퍼런스만 받아오게 되면
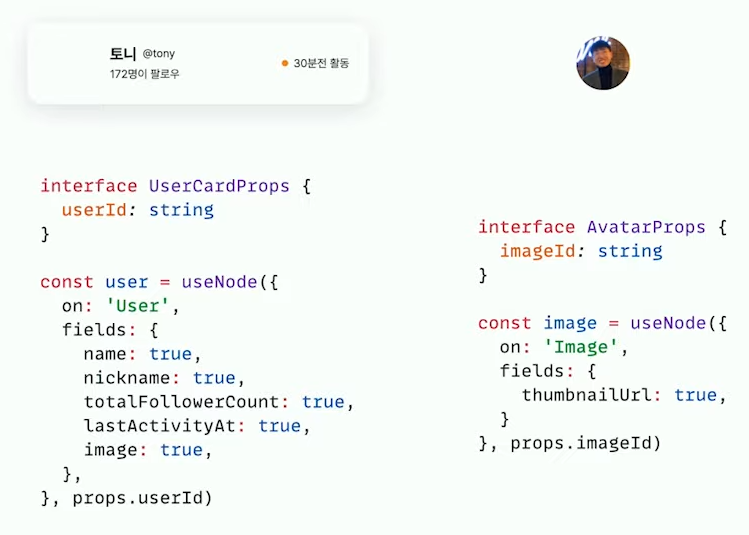
의존성이 느슨해지면서 훨씬 재사용성이 높아진 컴포넌트로 만들 수 있다.
재사용 하기
컴포넌트를 재사용하는 이유는 개발할 때 편리하기 위한 것보다 변경할 때 편리하기 위함 (유지보수)이라는 관점으로도 볼 수 있다.
그럼 먼저 변경될 만한 부분을 미리 예측하고 아주 만반의 준비를 해야 한다.
컴포넌트 변화의 방향성을 결정하는 것은 제품의 성격에 따라 다를수 있겠지만 대부분의 변화는 리모트 데이터 스키마가 변화하는 방향을 따라서 움직인다.
그렇다면 이러한 리모트 데이터 스키마 변화에 어떻게 대응할 수 있을까?
예를 들어 디자이너가 아래와 같은 스펙을 줬다고 가정해 보자.

왼쪽은 위에서 봤던 유저를 표현하는 컴포넌트 였고, 오른쪽은 새로 추가된 페이지를 표현하는 컴포넌트 이다.
이 둘은 얼핏봤을 때 상당히 비슷하게 생겼다. 하지만 이 둘이 의존하고 있는 리모트 스키마 데이터는 각각 유저, 페이지로 다르다.
이런 상황에서 기존에 있던 컴포넌트를 재사용할지, 복사해서 새 컴포넌트로 분리할 지 어떤게 더 나은 방법일까??
재사용 하는 경우
![image]()
이와 같은 상황이라면 해당 컴포넌트를 사용하는 곳이 어디인지, 잘 수정되었는지 여러 군데를 테스트해야 할 것이고, 페이지만 따로 구별하기 힘들기 때문에 가볍게 대응하기 어려울 수 있다.
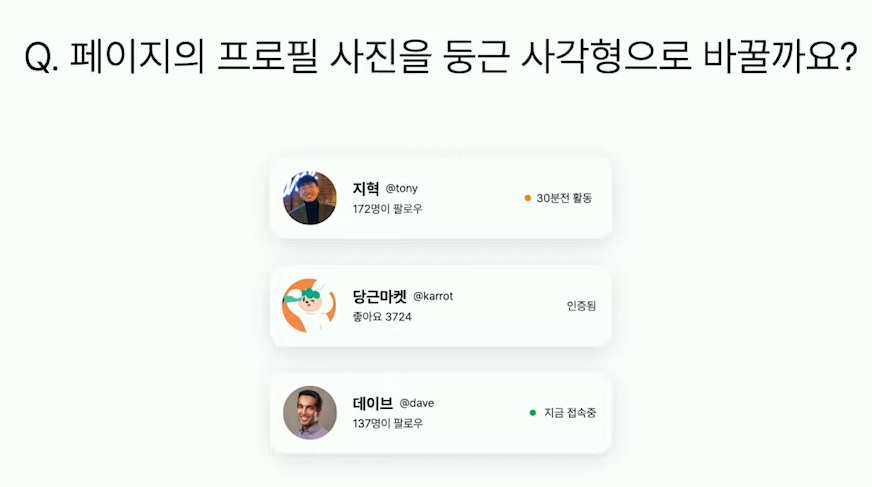
그래서 이 예시는 함께 변하면 안되는 것들이 특정 컴포넌트에 의존성으로 함께 존재하면서 발생했던 부작용 이슈를 잘 보여준다.
그렇다면 함께 변해야하는 것들과 따로 변해야하는 것들을 어떻게 구별할 수 있을까?
바로 모델 기준으로 컴포넌트를 분리하는 원칙이다. (같은 모델을 의존하는 컴포넌트의 경우 재사용하고, 다른 모델을 의존하는 컴포넌트는 별도로 분리한다.)
최종 정리
- 비슷한 관심사라면 가까운 곳에 두기
- 데이터를 ID 기반으로 정리하기
- 의존한다면 그대로 드러내기
- 모델 기준으로 컴포넌트 분리하기